Linux Scalability Project
Status report for January and February 1999
Center for Information Technology Integration
School of Information at the University of Michigan
The primary goal of this research is to improve the scalability and robustness of the Linux operating system to support greater network server workloads more reliably. We are specifically interested in single-system scalability, performance, and reliability of network server infrastructure products running on Linux, such as LDAP directory servers, IMAP electronic mail servers, and web servers, among others.
Summary
January 5th, 1999 was officially Day One for this project. We've continued our efforts to build strong relationships with Netscape server developers and the Linux community. Several small technical projects have been completed. And we've begun building our technological infrastructure.Milestones
Challenges
Understanding the purpose of research (project workscope)
During these last two months, our focus has shifted from determining and describing our project's goals and workscope to beginning our efforts. Even though we have a fairly complete working draft of the project workscope, there are several issues that continue to prevent the workscope from completely solidifying. Needless to say, there are many ambiguities about this work, and many complicating factors."Scope creep" is an ever-present danger. Few have a clear picture of Linux's true performance and scalability issues, and the image is always shifting as new Linux kernel releases are made. Linux kernel developers operate by feel, rather than on quantitative or historical analysis, since everyone knows that benchmarks can easily mislead even the most well-intentioned. Unfortunately, this prevents narrowly-focused development effort, since distraction is only the next bug fix away. And we all have our own agenda, from getting our products to market in a timely fashion, to proving that our way of analyzing a problem is the right way.
So many who are involved with our project are unfamiliar with, or untrusting of, the underlying rules of research projects like these. Netscape, as a company, hires many, many product developers, but few researchers. Netscape wants results, deliverables, execution. It's not clear to product-oriented managers exactly what value research can add. Often, researchers are asked to produce product deliverables, rather than to chase the results of exploration. Frustration results on both sides because there is a mismatch of expectations.
And the Linux community is almost anti-academic, charging that academics create unportable and unmaintainable code. Their suspicion is that once the measurements are taken and the simulations have completed, an academic's usefulness is finished. An academic never had to work with development methodolgy, defect counts, coding conventions, software portability issues, or within the constraints of a market.
The Linux kernel learning curve
The learning curve is still steep. Developers often don't respond to e-mail, problem reports, or technical questions because they are busy, or for other reasons. Documentation in the code or produced separately doesn't begin to help one understand some of the obscure techniques used to speed up kernel functions.But we do have a clearer window on what Linus will accept into the stock kernel distribution. He has made plain several guidelines that he uses to judge a modification or new feature.
Threaded signals v. NT completion ports
There are many complications involved with pushing out a software release as complex as a kernel. The problems of combining threads and asynchronicity at the application level have slipped off the Linux kernel development radar screen while the latest production branch of the Linux kernel stabilizes.It appears that there may be some room to crack the "must be POSIX-compliant" wagon-circle. As we become more familiar with Linux, especially in the area of threads and signals, it is clear that Linux does not implement a wholly POSIX-compliant API. But again, we must produce the numbers to breach the politics of "no NT allowed here", in order to suggest, and be believed, that completion ports are a superior software technology.
The CITI lab is now in a better position to begin analyzing the true nature of thread/event scalability. We now have a four CPU machine running Linux, a recent build of the server applications we want to test, and a reproducible way to stress large systems like this one. Reports from the directory team indicate that Linux DS performs as well as the other Unix ports; that is, somewhat less well than the same server running on NT. In the coming month, we hope to bring our test harness on-line to discover where Linux can offer better performance and scalability.
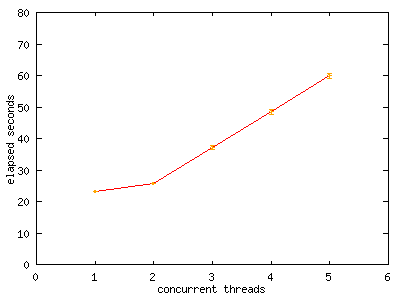
Performance graphs
Our experimental benchmark program ran multiple threads allocating and freeing heap memory at the same time. These graphs show nearly linear growth of elapsed time when adding more threads. This is what we would expect in a correctly operating two-CPU system.

Copyright 1999